
들어가며
구글에서는 프라이머리 키 기반의 조회 및 변경이 아주 높은 빈도로 실행되는 서비스가 많았는데, 이런 서비스는 매우 많은 트랜잭션을 동시에 실행하기 때문에 데드락 감지 스레드가 상당히 성능을 저하시킨다는 것을 알아냈다. 그리고 MySQL 서버의 소스코드를 변경해 데드락 감지 스레드를 비활성화할 수 있게 변경해서 사용.. - RealMySQL 8.0 중에서
얼마 전 RealMySQL 8.0 책을 읽다가 이 문장을 보고 의문이 생겼습니다. 아무리 느리다고 해도 구글 같은 기업이 MySQL의 핵심 안전장치 중 하나인 데드락 탐지를 아예 꺼버린다니, 이 데드락 탐지 메커니즘이 얼마나 비효율적이기에 그런 결정을 내렸을까요?
궁금증을 풀려고 MySQL InnoDB 엔진의 소스 코드까지 파헤쳤고, 그 과정에서 본 데드락 탐지의 흐름을 정리해보려 합니다.
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
이 오류 메시지를 본 적 있으신가요? 데드락이 발생하면 MySQL InnoDB 엔진이 자동으로 이를 잡아내고 해결합니다. 다만 이 데드락 탐지 메커니즘이 높은 동시성 환경에서는 심각한 성능 문제를 만들고, 구글이 이 기능을 비활성화한 이유도 여기에 있습니다.
MySQL InnoDB의 데드락 탐지 메커니즘이 왜 느린지, 실제 소스 코드를 따라가며 어떻게 동작하는지 깊이 들여다보겠습니다.
데드락(Deadlock)의 기본 개념
데드락이란?
데드락은 두 개 이상의 트랜잭션이 서로 보유한 잠금을 기다리며 무한정 대기하는 상황을 가리킵니다.
간단한 예시로 살펴보겠습니다.
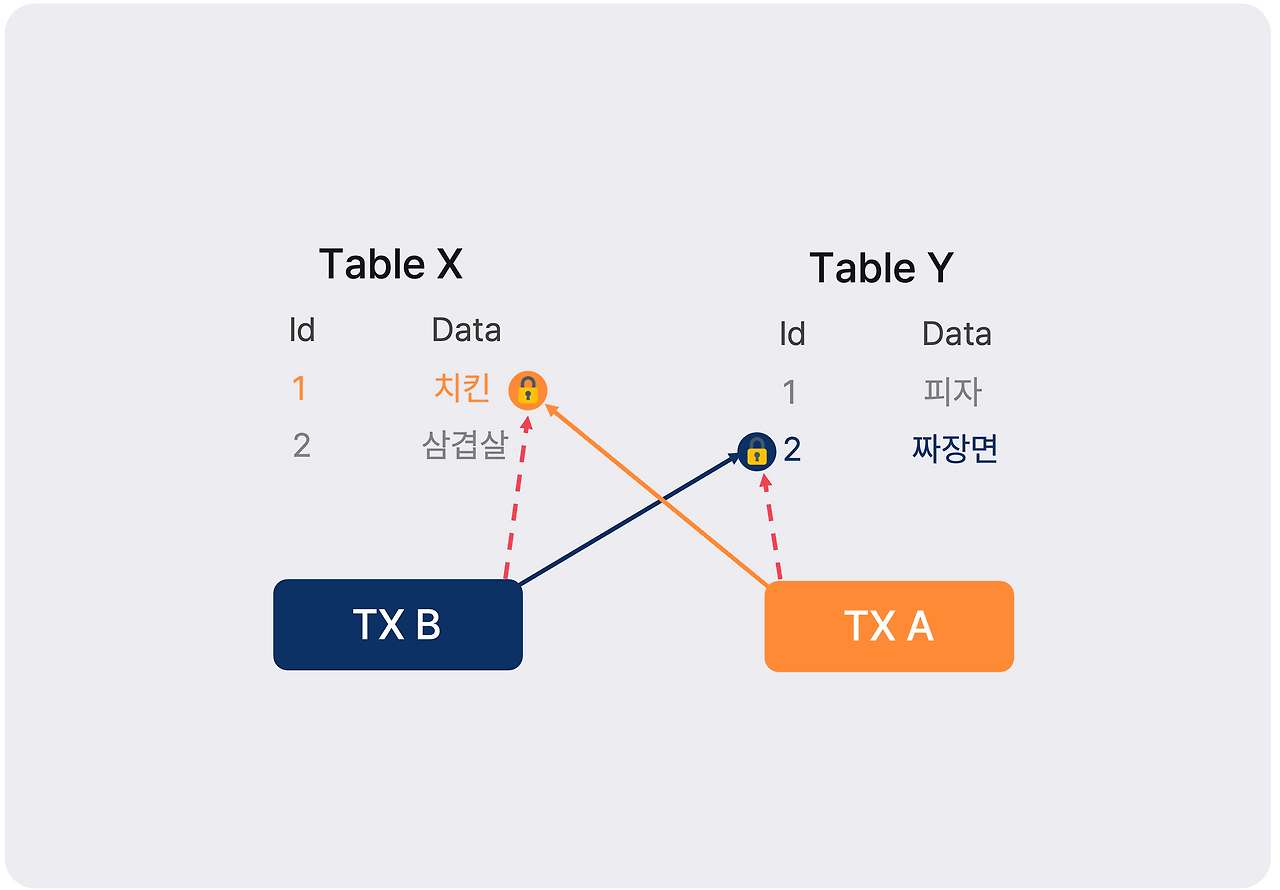
- 트랜잭션 A가 테이블 X의 행 1에 잠금을 획득
- 트랜잭션 B가 테이블 Y의 행 2에 잠금을 획득
- 트랜잭션 A가 테이블 Y의 행 2에 접근하려고 시도 (B가 잠금 중이라 대기)
- 트랜잭션 B가 테이블 X의 행 1에 접근하려고 시도 (A가 잠금 중이라 대기)
이렇게 서로가 서로를 기다리면 데드락이 발생합니다. 두 트랜잭션은 영원히 진행되지 못한 채 대기 상태에 머무릅니다.
InnoDB의 데드락 처리 방식
InnoDB는 두 가지 방식으로 데드락 문제를 해결합니다.
- 데드락 탐지(Deadlock Detection): 대기 그래프를 구성하여 순환을 찾아 데드락을 탐지하고, 희생자(victim)를 선택해 롤백
- 타임아웃(Timeout): 설정된 시간(innodb_lock_wait_timeout) 동안 잠금을 획득하지 못하면 트랜잭션 롤백
InnoDB는 기본적으로 데드락 탐지를 켜둔 채 동작합니다. 다만 이 탐지 방식이 고부하 환경에서 심각한 성능 저하로 이어진다는 점이 알려져 있습니다.
데드락 탐지 알고리즘의 작동 방식
InnoDB의 데드락 탐지가 어떻게 작동하고 왜 느린지 코드 레벨에서 살펴보겠습니다.
해당 글의 모든 내용은 mysql-server 8.4 버전의 InnoDB 소스코드 lock0lock.cc 를 바탕으로 작성되었습니다. 소스코드를 보면 구현 세부사항과 MySQL 엔지니어링 팀이 직면했던 다양한 기술적 고민들을 주석을 통해 확인하실 수 있으니 한번쯤 보시면 좋을 것 같습니다.
InnoDB 데드락 탐지의 작동 원리
InnoDB는 lock_wait_timeout_thread 함수로 데드락 탐지를 수행합니다.
void lock_wait_timeout_thread() {
int64_t sig_count = 0;
os_event_t event = lock_sys->timeout_event;
do {
// 1초에 한 번씩 타임아웃 검사
auto current_time = std::chrono::steady_clock::now();
if (std::chrono::seconds(1) <= current_time - last_checked_for_timeouts_at) {
last_checked_for_timeouts_at = current_time;
lock_wait_check_slots_for_timeouts();
}
// 데드락 탐지 및 처리
lock_wait_update_schedule_and_check_for_deadlocks();
// 최대 1초 대기 후 다시 실행
os_event_wait_time_low(event, std::chrono::seconds{1}, sig_count);
sig_count = os_event_reset(event);
} while (srv_shutdown_state.load() < SRV_SHUTDOWN_CLEANUP);
}이 스레드가 1초마다 실행되는 이유는 다음과 같습니다.
- 타이밍 밸런스: 데드락 탐지는 리소스를 많이 먹는 작업이라, 너무 자주 돌면 시스템 성능이 떨어지고 너무 드물게 돌면 데드락 상황이 오래 지속됩니다.
- 타임아웃 검사와의 동기화: lock_wait_check_slots_for_timeouts() 함수로 잠금 대기 타임아웃을 1초 단위로 검사하므로, 데드락 탐지도 같은 주기로 도는 편이 자연스럽습니다.
- 이벤트 기반 동작: os_event_wait_time_low는 최대 1초까지 대기하다가도 lock_set_timeout_event()가 호출되면 곧바로 깨어나 실행됩니다. 트랜잭션이 새로 잠금 대기 상태로 들어갔을 때 이런 호출이 일어납니다.
lock_wait_check_slots_for_timeouts() 함수는 사용자가 설정한 innodb_lock_wait_timeout 값(초 단위)에 따라 잠금 대기 상태인 트랜잭션들의 타임아웃을 검사하고 롤백합니다. 이 함수 자체는 1초마다 호출되어 검사를 수행하지만, 실제 타임아웃 값은 사용자가 설정한 innodb_lock_wait_timeout 값(기본값 50초)입니다.
특히 눈여겨볼 점은 lock_wait_request_check_for_cycles() 함수가 호출될 때 lock_set_timeout_event()가 트리거되어, 새로운 잠금 대기가 발생하면 데드락 탐지가 즉시 돌 수 있다는 사실입니다. 다음 코드에서 그 흐름이 드러납니다.
void lock_wait_request_check_for_cycles() { lock_set_timeout_event(); }데드락 탐지는 다음 두 가지 조건에서 발동됩니다.
- 1초 타이머에 의한 주기적 검사
- 새로운 잠금 대기가 발생했을 때의 즉시 검사
데드락 탐지 과정
1️⃣ 대기 트랜잭션 스냅샷 생성
첫 단계는 현재 잠금을 기다리는 모든 트랜잭션의 스냅샷을 만드는 일입니다.
static uint64_t lock_wait_snapshot_waiting_threads(
ut::vector<waiting_trx_info_t> &infos) {
infos.clear();
lock_wait_mutex_enter(); // 일관된 스냅샷을 위해 뮤텍스를 획득
const auto table_reservations = lock_wait_table_reservations;
for (auto slot = lock_sys->waiting_threads; slot < lock_sys->last_slot; ++slot) {
if (slot->in_use) {
auto from = thr_get_trx(slot->thr);
auto to = from->lock.blocking_trx.load();
if (to != nullptr) {
infos.push_back({from, to, slot, slot->reservation_no});
}
}
}
lock_wait_mutex_exit(); // 뮤텍스를 해제
return table_reservations;
}- 슬롯 순회: 대기 중인 모든 스레드 슬롯을 돌면서, 사용 중인 슬롯에서 트랜잭션 정보를 뽑아냅니다.
- slot->in_use: 슬롯이 현재 사용 중인지 확인합니다.
- from = thr_get_trx(slot->thr): 대기 중인 트랜잭션을 가져옵니다.
- to = from->lock.blocking_trx.load(): 트랜잭션 객체 내부의 lock.blocking_trx 필드에서 이 트랜잭션을 차단하고 있는 다른 트랜잭션(to)의 정보를 가져옵니다.
- infos.push_back(): 대기 관계 정보(대기 트랜잭션, 차단 트랜잭션, 슬롯, 예약 번호)를 벡터에 담습니다. 이 과정에서 벡터 용량이 부족하면 메모리 재할당이 일어납니다.
2️⃣ 잠금 대기 목록 구축
다음 단계는 트랜잭션 사이의 잠금 대기 그래프(Wait-For Graph)를 만드는 일입니다.
static void lock_wait_build_wait_for_graph(
ut::vector<waiting_trx_info_t> &infos, ut::vector<int> &outgoing) {
// 트랜잭션 수
const auto n = static_cast<uint>(infos.size());
// 결과 벡터 초기화
outgoing.clear();
outgoing.resize(n, -1);
// 트랜잭션 ID를 기준으로 정렬 - O(n log n) 연산
sort(infos.begin(), infos.end());
waiting_trx_info_t needle{};
// 각 트랜잭션에 대해 차단하는 트랜잭션 찾기
for (uint from = 0; from < n; ++from) {
// 현재 트랜잭션이 기다리는 트랜잭션 ID
needle.trx = infos[from].waits_for;
// 이진 검색으로 차단 트랜잭션 찾기 - O(log n) 연산
auto it = std::lower_bound(infos.begin(), infos.end(), needle);
// 찾지 못했으면 계속 진행
if (it == infos.end() || it->trx != needle.trx) {
continue;
}
// 해당 트랜잭션의 인덱스 계산 및 저장
auto to = it - infos.begin();
outgoing[from] = static_cast<int>(to);
}
}정렬 후에는 각 트랜잭션(from)이 대기하는 트랜잭션(needle.trx = infos[from].waits_for)을 찾고, 찾으면 해당 인덱스를 outgoing[from]에 저장합니다. 방향 그래프의 간선을 표현하는 방식입니다.
outgoing 배열은 각 트랜잭션이 어떤 트랜잭션을 기다리는지 나타내며, 사이클 탐지 알고리즘에서 핵심 자료가 됩니다.
3️⃣ 사이클 탐색 (데드락 탐지)
잠금 대기 그래프가 만들어지면, InnoDB는 그래프에서 사이클(데드락)을 찾습니다.
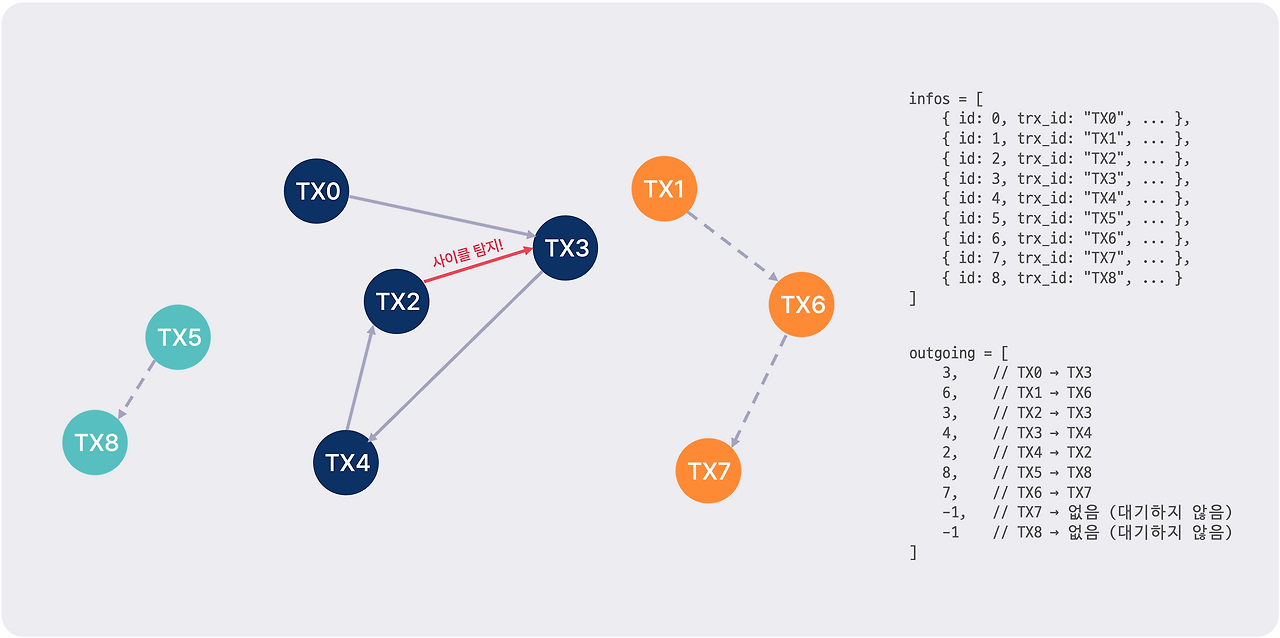
static void lock_wait_find_and_handle_deadlocks(
const ut::vector<waiting_trx_info_t> &infos,
const ut::vector<int> &outgoing,
ut::vector<trx_schedule_weight_t> &new_weights) {
// 사이클을 저장할 벡터
ut::vector<uint> cycle_ids;
// DFS 방문 상태를 추적할 배열
ut::vector<uint> colors;
colors.resize(n, 0);
uint current_color = 0;
// 각 트랜잭션을 시작점으로 DFS 실행
for (uint start = 0; start < n; ++start) {
// 이미 방문한 노드는 건너뜀
if (colors[start] != 0) {
continue;
}
// 새로운 색상으로 DFS 시작
++current_color;
// DFS를 통한 경로 탐색
for (int id = start; 0 <= id; id = outgoing[id]) {
// 아직 방문하지 않은 노드는 현재 색상으로 표시
if (colors[id] == 0) {
colors[id] = current_color;
continue;
}
// 현재 DFS에서 이미 방문한 노드를 다시 만남 -> 사이클 발견!
if (colors[id] == current_color) {
// 사이클의 모든 트랜잭션 ID 추출
lock_wait_extract_cycle_ids(cycle_ids, id, outgoing);
// 추가 검증 및 데드락 처리
if (lock_wait_check_candidate_cycle(cycle_ids, infos, new_weights)) {
MONITOR_INC(MONITOR_DEADLOCK);
} else {
MONITOR_INC(MONITOR_DEADLOCK_FALSE_POSITIVES);
}
}
// 그래프 순회 종료
break;
}
}
}이 함수는 변형된 DFS 알고리즘으로 사이클을 잡아냅니다.
- 색상 배열: colors 배열은 각 노드의 방문 상태를 추적합니다. 0은 방문하지 않음, 다른 양수는 현재 DFS 색상을 가리킵니다.
- 모든 노드에서 DFS 시작: 각 노드를 시작점 삼아 DFS를 돌려 가능한 모든 사이클을 잡아냅니다.
- 사이클 탐지 로직: 현재 DFS 색상(current_color)으로 이미 방문한 노드를 다시 만나면 사이클이 있다는 뜻입니다.
- 사이클 추출 및 검증: 사이클이 잡히면 lock_wait_extract_cycle_ids로 사이클의 모든 노드를 뽑고, lock_wait_check_candidate_cycle로 실제 데드락인지 검증한 뒤 처리합니다.
4️⃣ 데드락 후보 사이클 검증 (lock_wait_check_candidate_cycle)
사이클을 발견한 뒤에는 추가 검증이 필요합니다.
static bool lock_wait_check_candidate_cycle(
ut::vector<uint> &cycle_ids, const ut::vector<waiting_trx_info_t> &infos,
ut::vector<trx_schedule_weight_t> &new_weights) {
// 락 대기 뮤텍스 진입
lock_wait_mutex_enter();
// 사이클에 포함된 트랜잭션들이 여전히 슬롯에 있는지 확인
if (!lock_wait_trxs_are_still_in_slots(cycle_ids, infos)) {
// 슬롯에 없으면 뮤텍스 해제 후 false 반환
lock_wait_mutex_exit();
return false;
}
// 전역 배타적 래치 획득
locksys::Global_exclusive_latch_guard gurad{UT_LOCATION_HERE};
// 사이클에 포함된 트랜잭션들이 여전히 대기 중인지 확인
if (!lock_wait_trxs_are_still_waiting(cycle_ids, infos)) {
// 대기 중이 아니면 뮤텍스 해제 후 false 반환
lock_wait_mutex_exit();
return false;
}
// 락 대기 뮤텍스 해제
lock_wait_mutex_exit();
// 데드락 해결을 위한 희생 트랜잭션 선택 - 5번에서 설명
trx_t *const chosen_victim = lock_wait_choose_victim(cycle_ids, infos);
// 데드락 처리 및 새로운 가중치 계산 - 6번에서 설명
lock_wait_handle_deadlock(chosen_victim, cycle_ids, infos, new_weights);
return true;
}- 트랜잭션 슬롯 확인: lock_wait_trxs_are_still_in_slots 함수는 사이클의 모든 트랜잭션이 여전히 대기 슬롯에 있는지 확인합니다. 스냅샷을 만든 뒤 트랜잭션 상태가 바뀌었을 수 있어 필요한 절차입니다.
- 대기 상태 확인: lock_wait_trxs_are_still_waiting 함수는 트랜잭션이 여전히 잠금 대기 중인지 확인합니다. 트랜잭션은 슬롯에 남아 있더라도 대기 상태가 풀렸을 수 있습니다.
- 글로벌 래치 사용: Global_exclusive_latch_guard는 모든 잠금 관련 작업을 일시 중지시키는 강력한 래치입니다. 데드락 검증 중 시스템 상태가 바뀌지 않도록 보장하지만, 시스템 전체 성능에 영향을 줍니다.
1번의 대기 트랜잭션 스냅샷 생성 과정에서 Global_exclusive_latch_guard를 사용했다면 추가 검증은 필요하지 않을 것입니다. 하지만, 이는 매우 큰 성능 비용을 초래합니다. 따라서 InnoDB는 가벼운 뮤텍스(lock_wait_mutex)로 초기 스냅샷을 생성하고, 실제 데드락 가능성이 있을 때만 무거운 글로벌 래치를 사용하고 재확인하는 방식으로 타협점을 찾았습니다. 이 접근법은 약간의 추가 검증 작업을 필요로 하지만, 전체 시스템 성능을 크게 향상시킵니다.
5️⃣ 희생자 선택 과정
데드락이 확정되면 롤백할 트랜잭션(희생자)을 골라야 합니다.
static trx_t *lock_wait_choose_victim(
const ut::vector<uint> &cycle_ids,
const ut::vector<waiting_trx_info_t> &infos) {
// 희생될 트랜잭션을 저장할 포인터를 초기화
trx_t *chosen_victim = nullptr;
// 데드락 해결을 위해 희생자 선택 순서대로 트랜잭션 정렬
auto sorted_trxs = lock_wait_order_for_choosing_victim(cycle_ids, infos);
// 정렬된 트랜잭션들을 순회하며 희생자 선택
for (auto *trx : sorted_trxs) {
if (chosen_victim == nullptr) {
chosen_victim = trx;
continue;
}
// 현재 희생자나 검사 중인 트랜잭션이 고우선순위인 경우
if (trx_is_high_priority(chosen_victim) || trx_is_high_priority(trx)) {
// 우선순위 기반 중재 수행
auto victim = trx_arbitrate(trx, chosen_victim);
if (victim != nullptr) {
// 중재 결과에 따라 희생자 업데이트
if (victim == trx) {
chosen_victim = trx;
} else {
// 중재 결과가 현재 희생자와 동일한지 확인 (디버그용)
ut_a(victim == chosen_victim);
}
continue;
}
}
// 가중치 비교: 현재 트랜잭션의 가중치가 더 작으면 희생자로 선택
if (trx_weight_ge(chosen_victim, trx)) {
chosen_victim = trx;
}
}
// 선택된 희생 트랜잭션 반환
return chosen_victim;
}- 트랜잭션 정렬: lock_wait_order_for_choosing_victim 함수는 데드락 사이클의 트랜잭션을 특정 순서로 정렬합니다. 일관된 희생자 선택을 위해 필요한 단계입니다. 사이클에 가장 최근 참여한 트랜잭션(latest_pos)을 찾고, 그 다음 트랜잭션부터 시작하도록 사이클을 회전시킵니다. (데드락 사이클에서 가장 최근 참여한 트랜잭션부터 평가하여 일관된 희생자 선택이 가능하도록 함)
- 우선순위 처리: 고우선순위 트랜잭션이 있으면 중재(trx_arbitrate) 함수로 따로 처리합니다. 중요한 트랜잭션이 불필요하게 롤백되지 않도록 막아줍니다. (백업/복구 과정의 트랜잭션, 명시적으로 고우선순위로 표시된 트랜잭션 등)
- 가중치 비교: trx_weight_ge 함수는 두 트랜잭션의 "가중치"를 비교합니다. 가중치가 작은 트랜잭션이 희생자가 됩니다. (트랜잭션 수명, 변경된 행 수, 잠금 수 등을 고려하여 가중치 결정)
희생자 선택 알고리즘은 복잡하지만, 가장 적절한 트랜잭션을 롤백하려면 거쳐야 하는 절차입니다. 이 과정에서 "가중치가 작은" 트랜잭션, 곧 더 적은 작업을 수행한 트랜잭션이 희생자가 됩니다.
6️⃣ 데드락 처리
마지막으로, 희생자가 정해지면 데드락을 처리합니다.
static void lock_wait_handle_deadlock(
trx_t *chosen_victim, const ut::vector<uint> &cycle_ids,
const ut::vector<waiting_trx_info_t> &infos,
ut::vector<trx_schedule_weight_t> &new_weights) {
// 데드락 사이클에 포함된 트랜잭션들의 가중치를 업데이트
lock_wait_update_weights_on_cycle(chosen_victim, cycle_ids, infos,
new_weights);
// 데드락 발생 및 해결에 대한 알림 처리
lock_notify_about_deadlock(
lock_wait_trxs_rotated_for_notification(cycle_ids, infos), chosen_victim);
// 선택된 희생자 트랜잭션을 롤백하여 데드락 해결
lock_wait_rollback_deadlock_victim(chosen_victim);
}- 가중치 업데이트: lock_wait_update_weights_on_cycle 함수는 사이클의 모든 트랜잭션 가중치를 업데이트합니다. 희생자가 롤백된 후 남은 트랜잭션의 가중치를 조정하는 단계입니다.
- 데드락 알림: lock_notify_about_deadlock 함수는 데드락 발견을 로깅하고 알립니다.
- 희생자 롤백: lock_wait_rollback_deadlock_victim 함수는 선택된 희생자 트랜잭션을 롤백합니다.
견고하지만 복잡한 데드락 탐지 과정
InnoDB의 데드락 탐지 과정은 충분히 견고하고 잘 짜여 있지만, 다음과 같은 구조적 문제를 안고 있습니다.
- 시간 복잡도 데드락 탐지는 대기 그래프 구축과 사이클 탐지 과정에서 높은 시간 복잡도를 가집니다. 대기 중인 트랜잭션 수가 늘수록 처리 시간이 기하급수적으로 길어집니다. 소스 코드에서 본 것처럼, 정렬·그래프 구축·DFS 사이클 탐지가 한 묶음으로 돌면서 성능을 저하시킵니다.
- 글로벌 래치의 영향 데드락 후보를 검증하는 과정에서 Global_exclusive_latch_guard를 사용합니다. 이 래치가 획득되는 순간 InnoDB 엔진의 모든 트랜잭션 처리가 일시 중지됩니다. 초당 수만 건의 트랜잭션을 처리하는 환경에서 이는 심각한 병목입니다.
- 메모리 관리 오버헤드 데드락 탐지 과정에서 infos, outgoing, colors, cycle_ids 같은 여러 벡터를 동적으로 할당하고 관리합니다. 고성능 환경일수록 메모리 단편화와 CPU 캐시 효율 저하로 이어집니다. 데드락 탐지가 자주 일어날수록 오버헤드가 쌓입니다.
- 빈번한 탐지 실행 데드락 탐지는 1초마다 주기적으로 돌고, 새로운 잠금 대기가 생길 때마다 추가로 트리거됩니다. 고부하 환경에서는 거의 연속적인 탐지로 이어져 시스템 자원을 꾸준히 갉아먹습니다.
데드락 탐지의 대안: 잠금 대기 타임아웃 최적화
데드락 탐지를 끄는 대신 잠금 대기 타임아웃(innodb_lock_wait_timeout)을 적절히 설정하는 방법이 있습니다.
- 잠금 대기 타임아웃 최적화: 데드락 탐지를 비활성화한 환경에서는 innodb_lock_wait_timeout 값을 기본값 50초에서 더 짧은 시간(보통 1~5초)으로 설정합니다. 이 방법은 데드락 상황에서 무한 대기를 막고 신속하게 트랜잭션을 롤백시켜 시스템 자원을 효율적으로 회수합니다.
- 성능과 타임아웃 간의 균형: 타임아웃을 너무 짧게 잡으면 정상 트랜잭션도 자주 실패합니다. 반대로 너무 길게 잡으면 데드락 상황에서 리소스가 오래 잠깁니다. 워크로드 특성에 맞는 값을 찾는 작업이 중요합니다.
- 구현 방법: MySQL 5.7.15부터는 innodb_deadlock_detect 파라미터로 데드락 탐지를 끌 수 있고, 이때 innodb_lock_wait_timeout 설정은 다음과 같이 가능합니다.
SET GLOBAL innodb_deadlock_detect = OFF;
SET GLOBAL innodb_lock_wait_timeout = 5; -- 5초로 설정이 접근은 트랜잭션 패턴이 단순하고 대규모 동시성이 필요한 환경에서 특히 쓸 만하며, 데드락 탐지 알고리즘의 복잡성에서 오는 오버헤드를 피해 갑니다.
트레이드오프 이해하기
데드락 탐지 비활성화는 성능과 안전성 사이의 트레이드오프입니다. 구글처럼 극단적 성능 요구사항을 안은 특수한 워크로드에서는 데드락 탐지를 끄고 짧은 타임아웃과 애플리케이션 레벨 재시도 로직을 쓰는 전략이 잘 들어맞습니다.
다만 복잡한 트랜잭션 패턴을 가진 일반적인 애플리케이션에서는 데드락 탐지의 안전성이 성능 이점보다 무겁습니다. 시스템 특성과 요구사항을 함께 살피는 신중한 판단이 필요합니다.
MySQL InnoDB의 데드락 탐지 알고리즘 코드를 따라가 보니, 구글이 이를 끈 결정이 얼마나 합리적이었는지 가늠이 됩니다. 다만 모든 시스템에 통하는 답은 아니고, 특정 조건에서만 권할 만한 비교적 과감한 최적화 전략이라는 점은 함께 기억해 둘 만합니다.