
Java 21 출시
Java 21이 2023년 9월 19일에 정식 출시되었습니다. Java 17 이후로 새롭게 자리잡은 LTS(Long-Term Support) 버전이며, 다양한 개선과 새 기능을 담고 있습니다. 이번 글에서는 JDK 17 이후부터 JDK 21까지 통합된 JEP(JDK Enhancement Proposal) 가운데 개발자가 코드를 쓸 때 곧바로 체감하게 되는 주요 기능을 살펴봅니다.
JEP는 "JDK Enhancement Proposal"의 약자로, Java 플랫폼에 새 기능이나 개선·변경을 제안하는 공식 절차입니다. Java 언어, 라이브러리, 도구, JDK 전반에 걸친 개선을 다루며, 새 기능을 도입하거나 기존 기능을 다듬는 데 핵심 역할을 합니다. Java 커뮤니티는 JEP 절차에 따라 체계적으로 혁신을 이어가며, 제안 내용은 폭넓은 토론과 검토를 거쳐 채택됩니다.
1. JEP 440: 레코드 패턴(Record Patterns)
JDK 16에서 instanceof 연산자에 패턴 매칭이 도입됐습니다.
if(obj instanceof Name name) {
name.first(); name.last();
}JDK 21부터는 레코드 패턴이 추가됩니다. 레코드 패턴은 자바의 패턴 매칭 기능을 확장해, 레코드 타입의 값을 더 쉽게 분해하고 다루게 해줍니다.
- 객체 분해: 레코드 객체의 구성 요소를 한 번에 추출
- 중첩 패턴: 복잡한 데이터 구조도 단일 패턴으로 매칭
- var 키워드 지원: 타입 추론으로 코드를 더 간결하게
public class RecordPatternExample {
record Point(int x, int y) {}
record Rectangle(Point upperLeft, Point lowerRight) {}
public static void printRectangleCoordinates(Object obj) {
if (obj instanceof Rectangle(Point(var x1, var y1), Point(var x2, var y2))) {
System.out.printf("Upper left: (%d, %d), Lower right: (%d, %d)%n", x1, y1, x2, y2);
}
}
public static void main(String[] args) {
Rectangle rectangle = new Rectangle(new Point(0, 5), new Point(10, 0));
printRectangleCoordinates(rectangle);
// switch 문과 함께 사용
Object shape = new Point(3, 4);
String description = switch (shape) {
case Point(var x, var y) when x == y -> "Square point at " + x;
case Point(var x, var y) -> "Point at (" + x + ", " + y + ")";
default -> "Unknown shape";
};
System.out.println(description);
}
}이 예제는 레코드 패턴으로 복잡한 객체 구조를 손쉽게 분해하고 다루는 방법을 보여줍니다. instanceof와 switch 문 모두에서 레코드 패턴을 쓸 수 있어, 데이터 중심 프로그래밍이 한층 간결하고 명확해집니다.
몇 가지 주의할 점이 있습니다.
- 패턴 매칭 실패 시 MatchException이 발생하므로 적절한 예외 처리가 필요
- 중첩 패턴을 과하게 쓰면 코드 가독성이 떨어지므로 적정 수준에서 사용
2. JEP 441: 패턴 매칭 for switch (Pattern Matching for switch)
JDK 17에서 switch 문 기반 패턴 매칭이 프리뷰로 제공됐습니다.
JDK 21에서는 when 키워드를 활용한 가드 조건 등이 함께 정식 기능으로 포함됩니다. switch 문의 표현력이 크게 늘어, 데이터의 구조와 타입에 따라 더 세밀하고 유연한 분기 처리가 가능합니다. 복잡한 if-else 구조를 간소화하면서, 다양한 타입의 값을 손쉽게 분기 처리할 수 있습니다.
- 다양한 타입 지원: 기본 타입은 물론 참조 타입에도 switch 문 사용 가능
- null 처리: null 값을 명시적으로 처리
- 가드 조건: when 키워드로 추가 조건 지정
- 타입 패턴과 레코드 패턴 결합: 복잡한 객체 구조에도 패턴 매칭 가능
public class PatternMatchingForSwitchExample {
sealed interface Shape permits Circle, Rectangle, Triangle {}
record Circle(double radius) implements Shape {}
record Rectangle(double width, double height) implements Shape {}
record Triangle(double base, double height) implements Shape {}
public static double calculateArea(Shape shape) {
return switch (shape) {
case Circle c -> Math.PI * c.radius() * c.radius();
case Rectangle r -> r.width() * r.height();
case Triangle t -> 0.5 * t.base() * t.height();
case null -> 0;
};
}
public static void describeShape(Object obj) {
switch (obj) {
case Circle c when c.radius() > 5 ->
System.out.println("Large circle");
case Circle c ->
System.out.println("Small circle");
case Rectangle(var width, var height) when width == height ->
System.out.println("Square");
case Rectangle r ->
System.out.println("Rectangle: " + r.width() + "x" + r.height());
case Triangle t ->
System.out.println("Triangle with base " + t.base());
case String s ->
System.out.println("String: " + s);
case null ->
System.out.println("Null object");
default ->
System.out.println("Unknown shape");
}
}
public static void main(String[] args) {
Shape circle = new Circle(10);
Shape rectangle = new Rectangle(4, 5);
Shape square = new Rectangle(3, 3);
Shape triangle = new Triangle(5, 8);
System.out.println("Circle area: " + calculateArea(circle));
System.out.println("Rectangle area: " + calculateArea(rectangle));
System.out.println("Triangle area: " + calculateArea(triangle));
describeShape(circle);
describeShape(rectangle);
describeShape(square);
describeShape(triangle);
describeShape("Not a shape");
describeShape(null);
}
}이 예제는 패턴 매칭 for switch의 다양한 기능을 보여줍니다. 타입 패턴, 레코드 패턴, null 처리, 가드 조건을 활용해 복잡한 객체 구조와 조건을 다루는 방식을 확인할 수 있습니다.
switch 패턴 매칭을 쓰기 전에 짚어둘 점이 있습니다.
1. 패턴 지배 (Pattern Dominance) 패턴 매칭 switch 문에서는 case 순서가 중요합니다. 더 구체적인 패턴이 앞에 와야 하며, 이를 패턴 지배라고 부릅니다. 예제의 describeShape 메소드를 보면
case Circle c when c.radius() > 5 ->
System.out.println("Large circle");
case Circle c ->
System.out.println("Small circle");이 두 case의 순서를 바꾸면 "Large circle" case는 절대 실행되지 않습니다. 컴파일러는 이런 상황을 감지해 에러를 냅니다.
2. 완전성 (Exhaustiveness)
패턴 매칭 switch는 가능한 모든 경우를 처리해야 합니다. 이를 완전성(exhaustiveness)이라고 합니다.
sealed interface Shape permits Circle, Rectangle, Triangle {}
public static double calculateArea(Shape shape) {
return switch (shape) {
case Circle c -> Math.PI * c.radius() * c.radius();
case Rectangle r -> r.width() * r.height();
case Triangle t -> 0.5 * t.base() * t.height();
case null -> 0;
};
}예제의 Shape 인터페이스는 sealed로 선언되어 있습니다. 그래서 calculateArea 메소드는 Shape의 모든 하위 타입을 처리해야 합니다. Circle, Rectangle, Triangle을 빠짐없이 다루지 않으면 컴파일 에러가 납니다.
새 타입이 추가될 때 컴파일러가 누락된 케이스를 알려준다는 장점이 있고, 모든 케이스를 명시적으로 처리하게 되니 코드 의도도 또렷해집니다.
default case로 처리되지 않은 모든 타입을 한 번에 묶어 다룰 수도 있지만, 새 케이스가 추가돼도 컴파일러 경고를 받지 못할 수 있어 신중하게 써야 합니다.
이런 메커니즘은 컴파일 시점에 타입 안정성과 패턴 매칭의 완전성을 검사해 런타임 오류를 줄이고 코드의 견고성을 높입니다. 결과적으로 개발자의 의도치 않은 실수를 미리 막아주는 안전장치 역할을 한다고 볼 수 있겠네요.
3. JEP 431: 순차 컬렉션(Sequenced Collections)
Java의 컬렉션 프레임워크에는 오랫동안 요소 순서가 정의된 컬렉션 타입을 나타내는 단일 인터페이스가 없었습니다. List와 Deque는 순서를 정의하지만, 이들의 공통 상위 타입인 Collection은 순서를 정의하지 않습니다. Set도 순서를 정의하지 않지만, LinkedHashSet 같은 일부 구현체는 순서를 가집니다. 그래서 API를 설계할 때 순서 있는 컬렉션을 표현하기 어려웠고, 작업 방식의 일관성도 부족했습니다.
JDK 21에서 새로 추가된 순차 컬렉션(SequencedCollection) 은 Java 컬렉션 프레임워크에 순서 있는 컬렉션을 위한 일관된 API를 제공합니다. 첫 번째 요소·마지막 요소 접근과 역순 처리 등이 모든 순차 컬렉션에서 같은 방식으로 가능해집니다.
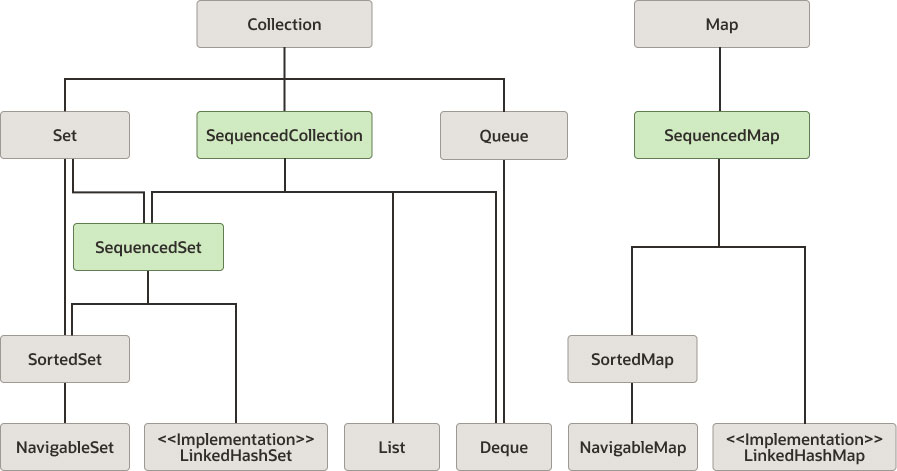
순차 컬렉션과 관련해 3가지 인터페이스가 추가되었습니다.
- SequencedCollection<E>
- SequencedSet<E>
- SequencedMap<K,V>
List 인터페이스는 SequencedCollection을 직접 상속합니다. 모든 List 구현체가 본질적으로 요소 순서를 유지하기 때문입니다. SequencedCollection이 List의 상위 인터페이스가 되면서, 순서 있는 다른 컬렉션 타입과 List 사이에 공통 상위 타입이 생겼습니다. 덕분에 순서 있는 컬렉션들을 일관된 방식으로 다룰 수 있게 됐습니다.
Set은 기본적으로 요소 순서를 보장하지 않으므로 SequencedCollection을 직접 상속하지 않습니다. 다만 SortedSet이나 LinkedHashSet처럼 순서를 유지하는 일부 Set 구현체를 위해 SequencedSet 인터페이스가 도입됐습니다. SequencedSet은 Set과 SequencedCollection을 모두 상속해, 순서 있는 Set의 성격을 드러냅니다.
Map 인터페이스도 기본적으로 순서를 보장하지 않습니다. 그래서 SequencedMap이 Map의 하위 인터페이스로 새로 정의되어, LinkedHashMap처럼 순서를 유지하는 Map 구현체에 쓰일 인터페이스를 제공합니다. SortedMap은 SequencedMap을 상속받아, 정렬된 상태를 유지하면서도 순차 접근 기능을 함께 제공합니다.
Queue 인터페이스는 특정 순서(FIFO)로 요소를 처리하지만, 임의 요소에 접근하는 기능이 없으므로 SequencedCollection을 상속하지 않습니다. 반면 Deque(Double Ended Queue)는 양쪽 끝에서 요소를 추가하고 제거할 수 있어 SequencedCollection의 개념과 잘 맞아 이를 구현합니다.
구현체 쪽을 보면 LinkedHashSet은 SequencedSet의 구현체로, LinkedHashMap은 SequencedMap의 구현체로 자리잡습니다. 두 클래스 모두 요소나 키의 삽입 순서를 유지한다는 특성 덕분입니다.
Sequenced Collections의 핵심 인터페이스는 다음과 같이 정의됩니다.
interface SequencedCollection<E> extends Collection<E> {
// 새로운 메소드
SequencedCollection<E> reversed();
// Deque에서 승격된 메소드들
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}
interface SequencedSet<E> extends Set<E>, SequencedCollection<E> {
SequencedSet<E> reversed(); // 공변 반환 타입
}
interface SequencedMap<K,V> extends Map<K,V> {
// 새로운 메소드
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// NavigableMap에서 승격된 메소드들
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}기존에는 아래 표처럼 첫 번째 요소와 마지막 요소를 가져오는 방식이 컬렉션마다 제각각이었고, 어떤 곳은 명확하지 않거나 아예 빠져 있었습니다.
| 첫번째 요소 | 마지막 요소 | |
|---|---|---|
| List | list.get(0) | list.get(list.size() - 1) |
| Deque | deque.getFirst() | deque.getLast() |
| SortedSet | sortedSet.first() | sortedSet.last() |
| LinkedHashSet | linkedHashSet.iterator().next() | // missing |
이제 Sequenced Collections API로 일관되게 접근할 수 있습니다. 새 인터페이스들은 getFirst()와 getLast() 메서드를 제공해, 모든 순차 컬렉션에서 같은 방식으로 첫 번째·마지막 요소에 접근하게 해줍니다.
여기에 reversed() 메서드도 눈에 띕니다. 컬렉션 요소를 역순으로 보여주는 뷰를 돌려주는 기능인데, 원본 컬렉션의 순서를 실제로 바꾸지 않고 역순으로 탐색할 새 뷰를 반환합니다.
기존 컬렉션 프레임워크의 역순 처리는 컬렉션 타입마다 일관성이 떨어졌고, 일부 컬렉션은 구현이 복잡하거나 내장 메서드가 없어 개발자가 직접 로직을 짜야 했습니다. 때로는 전체 컬렉션을 복사해 재정렬하는 비효율적 방식까지 동원해 성능과 가독성에 부담이 됐습니다.
reversed() 메서드의 핵심은 '뷰(view)' 개념입니다. 원본 컬렉션을 들여다보는 '윈도우' 또는 '렌즈' 같은 역할이며, 데이터를 다른 시각으로 보여주되 실제로 복사하거나 재배열하지는 않습니다. 메모리를 효율적으로 쓰며, 원본 컬렉션의 변경 사항이 역순 뷰에 곧바로 반영됩니다.
가령 LinkedHashSet에 reversed()를 호출하면 요소를 마지막부터 첫 번째까지 역순으로 순회하는 뷰가 돌아옵니다. 이 뷰로 반복자나 스트림을 만들면 요소가 역순으로 처리됩니다. 실제 데이터의 순서를 바꾸지 않으니 대규모 컬렉션에서도 효율적으로 동작합니다.
간단한 사용 예시를 살펴봅시다.
SequencedCollection<String> sequencedList = new ArrayList<>(List.of("A", "B", "C"));
System.out.println(sequencedList.getFirst()); // 출력: A
System.out.println(sequencedList.getLast()); // 출력: C
sequencedList.addFirst("Z");
sequencedList.addLast("D");
System.out.println(sequencedList); // 출력: [Z, A, B, C, D]
// reversed() 메서드 사용
for (String s : sequencedList.reversed()) {
System.out.print(s + " "); // 출력: D C B A Z
}
System.out.println();
// SequencedSet 사용 예시
SequencedSet<Integer> sequencedSet = new LinkedHashSet<>(Set.of(1, 2, 3, 4, 5));
System.out.println(sequencedSet.getFirst()); // 출력: 1
System.out.println(sequencedSet.getLast()); // 출력: 5
// SequencedMap 사용 예시
SequencedMap<String, Integer> sequencedMap = new LinkedHashMap<>();
sequencedMap.put("One", 1);
sequencedMap.put("Two", 2);
sequencedMap.putFirst("Zero", 0);
sequencedMap.putLast("Three", 3);
System.out.println(sequencedMap.firstEntry()); // 출력: Zero=0
System.out.println(sequencedMap.lastEntry()); // 출력: Three=3
// 역순 맵 순회
for (var entry : sequencedMap.reversed().entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}쓸 때 짚어둘 점이 있습니다.
1. SortedSet과 SortedMap의 제한사항
SortedSet과 SortedMap은 요소가 특정 순서(주로 자연 순서나 지정된 Comparator 순서)로 정렬된 컬렉션입니다. 여기서는 요소의 위치가 그 값에 따라 결정됩니다.
예를 들어
SortedSet<Integer> sortedSet = new TreeSet<>();
sortedSet.add(3);
sortedSet.add(1);
sortedSet.add(2);
System.out.println(sortedSet); // 출력: [1, 2, 3]
sortedSet.addFirst(5); // UnsupportedOperationException 발생요소들이 자동으로 오름차순 정렬됩니다. 그러니 addFirst()나 addLast() 같은 메서드는 이런 컬렉션의 본질과 충돌합니다. 요소를 추가할 때 위치는 값에 따라 정해져야 하기 때문입니다. 그래서 이 메서드들은 해당 컬렉션에서 지원되지 않고, 호출하면 예외를 냅니다.
실제로 SortedSet의 내부를 들여다보면 다음처럼 UnsupportedOperationException을 던지는 모습이 확인됩니다.
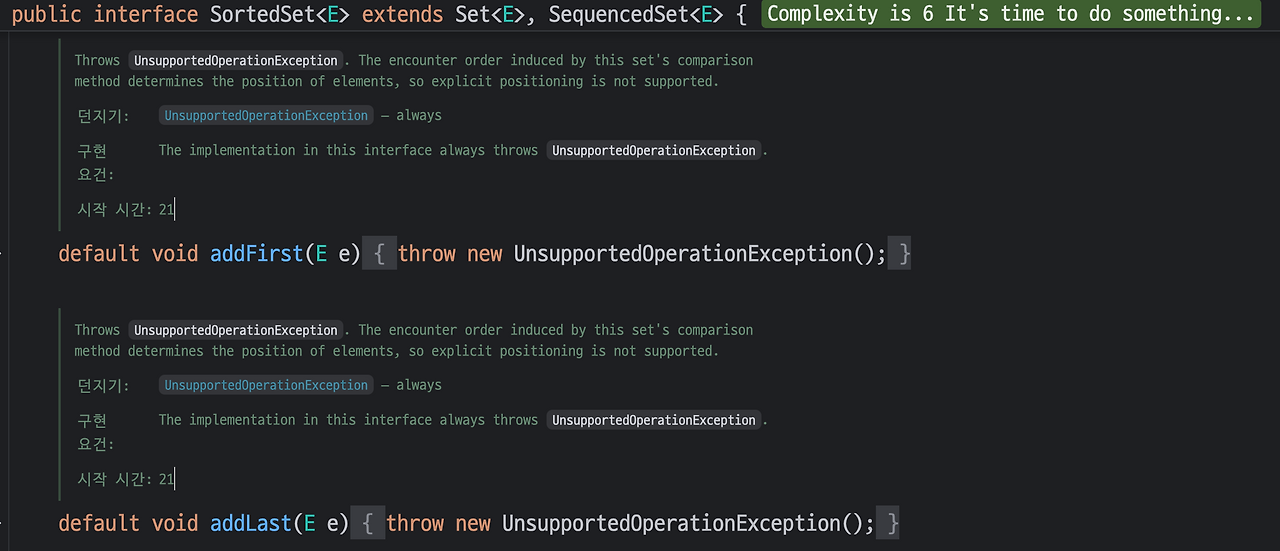
IDE에서도 메서드 사용 시 별도 경고를 띄우지 않고 빌드도 성공하므로, 런타임에 예외가 터질 수 있다는 점을 꼭 확인해야 합니다.
2. LinkedHashSet의 특별한 동작
LinkedHashSet은 요소 삽입 순서를 유지하는 Set입니다. 보통 Set은 중복을 허용하지 않지만, LinkedHashSet의 addFirst()와 addLast() 메서드는 이미 존재하는 요소에 대해 특별하게 동작합니다.
LinkedHashSet<String> set = new LinkedHashSet<>(Arrays.asList("A", "B", "C"));
System.out.println(set); // 출력: [A, B, C]
set.addFirst("B"); // B는 이미 존재하지만, 이 호출은 B를 맨 앞으로 이동시킵니다.
System.out.println(set); // 출력: [B, A, C]
set.addLast("A"); // A는 이미 존재하지만, 이 호출은 A를 맨 뒤로 이동시킵니다.
System.out.println(set); // 출력: [B, C, A]
set.add("B"); // 이 호출에서는 B가 원래 자리에 위치합니다
System.out.println(set); // 출력: [B, C, A]이 동작은 요소를 새로 더하는 게 아니라 기존 요소의 위치를 옮기는 것입니다. Set의 일반적 동작과 다르므로 쓸 때 주의해야 합니다.
이러한 특별한 동작은 각 컬렉션의 성격에 맞춰 설계됐지만, 개발자가 예상하지 못한 결과를 부를 수 있으니 주의 깊게 써야 합니다.
4. JEP 444: 가상 스레드(Virtual Threads)
JDK 19에서 가상 스레드가 프리뷰로 제공됐고, JDK 21에서 드디어 정식 기능으로 자리잡았습니다!
Java 개발자들은 거의 30년 동안 서버 애플리케이션의 동시성 처리를 위해 스레드를 써왔습니다. 하지만 전통적인 스레드 모델은 현대 애플리케이션의 요구사항을 따라가는 데 한계를 보여 왔습니다.
1. OS 스레드와 1:1 매핑으로 인한 높은 리소스 소비
전통적인 Java 스레드 모델에서는 각 Java 스레드가 OS 스레드 하나와 1:1로 매핑됩니다. 이런 구조에서 다음과 같은 문제가 생깁니다.
- 메모리 소비: 각 OS 스레드는 기본적으로 약 1MB의 스택 메모리를 씁니다. 따라서 1,000개의 스레드를 만들면 스택만으로도 약 1GB가 듭니다.
- 컨텍스트 스위칭 오버헤드: OS 스레드 사이의 컨텍스트 스위칭은 비용이 큰 작업입니다. 스레드 수가 늘수록 스위칭 빈도도 잦아져 시스템 성능이 떨어질 수 있습니다.
- 생성·소멸 비용: OS 스레드를 만들고 없애는 비용도 만만치 않습니다. 그래서 스레드의 동적 생성·소멸이 제한되고, 보통은 스레드 풀을 씁니다.
2. 제한적인 동시 요청 처리 능력
OS 스레드 수가 제한적이니, 동시에 처리할 수 있는 요청 수도 제한됩니다.
- 스레드 수 제한: 대부분의 운영 체제는 프로세스당 만들 수 있는 스레드 수를 제한합니다. 리눅스의 경우 기본적으로 프로세스당 약 32,000개 수준입니다.
- 리소스 경쟁: 스레드 수가 늘면 CPU와 메모리 같은 시스템 리소스 경쟁이 심해지고, 시스템 성능이 떨어집니다.
- I/O 블로킹: 전통적인 스레드 모델에서 I/O 작업은 해당 스레드를 블로킹합니다. I/O 바운드 작업이 많은 애플리케이션은 많은 스레드가 대부분의 시간을 대기 상태로 보내, 리소스가 낭비됩니다.
3. 스레드 풀을 써도 여전한 확장성 한계
스레드 풀은 위 문제들을 줄이려고 널리 쓰는 기술이지만, 한계는 남아 있습니다.
스레드 풀은 미리 만들어 둔 재사용 가능한 스레드들을 관리하는 메커니즘으로, 작업 요청이 들어오면 풀에서 가용 스레드에 할당해 처리합니다. 스레드 생성·소멸의 오버헤드를 줄이고 자원 사용을 효율적으로 관리해 시스템 안정성을 높이는 게 주된 목적입니다. Java에서는 ExecutorService 인터페이스로 손쉽게 구현할 수 있고, 고정 크기 풀이나 캐시 풀 등 여러 형태로 씁니다.
- 고정된 병렬성: 대부분의 스레드 풀은 고정된 수의 스레드를 씁니다. 동시에 처리할 작업 수가 그만큼 제한됩니다.
- 스레드 블로킹: 풀의 모든 스레드가 I/O 같은 블로킹 작업으로 대기 중이라면, 새 작업은 처리되지 못하고 줄을 서야 합니다.
- 리소스 낭비: 작업량이 적을 때도 풀의 모든 스레드가 그대로 살아 있어 리소스가 낭비될 수 있습니다.
- 튜닝의 어려움: 최적의 풀 크기를 정하는 일은 쉽지 않습니다. 너무 작으면 성능이 떨어지고, 너무 크면 리소스가 낭비됩니다.
이런 문제들 탓에 전통적인 스레드 모델로는 동시성이 많이 요구되는 현대 서버 애플리케이션의 요구를 감당하기 어려웠습니다. 한계를 넘어서고자 Java 19부터 가상 스레드가 도입됐습니다. 가상 스레드는 JEP 425에서 처음 제안되어 preview로 제공됐고, JEP 436을 거쳐 JEP 444에서 최종 확정됐습니다.
가상 스레드는 Java 런타임이 관리하는 경량 스레드입니다.
기존의 정통 스레드와 비교하며 가상 스레드의 특징과 구조를 자세히 살펴봅시다.
| 항목 | 정통 스레드 모델 | 가상 스레드 모델 |
|---|---|---|
| OS 스레드와의 관계 | 1:1 매핑 (Java 스레드 ↔ OS 스레드) | 1:M매핑 (많은 가상 스레드가 적은 OS 스레드를 공유) |
| 메모리 사용 | 고정된 스택 크기(약 1MB), 스레드 수 제한 | 메모리 효율적 사용, 수백만 개의 가상 스레드 생성 가능 |
| 블로킹 작업 처리 | OS 스레드 전체가 블록됨 | 가상 스레드만 블록되고, OS 스레드는 다른 작업 처리 |
| 스케쥴링 | OS의 스케줄러에 의해 관리 | Java 런타임 스케줄러(ForkJoinPool)로 관리 |
| 생성 및 관리 | 생성 비용이 높아 스레드 풀로 관리 | 생성 비용이 낮아 필요 시 생성 및 폐기 가능, 스레드 풀 필요 없음 |
| 프로그래밍 모델 | 비동기 프로그래밍 모델 사용 | 동기적 프로그래밍 모델로 높은 동시성 구현 가능 |
| 리소스 사용 효율성 | OS 스레드 수 제한으로 리소스 활용에 제약 | 많은 수의 동시 작업 처리로 하드웨어 리소스 효율적 사용 |
정통 스레드 vs 가상 스레드의 구조 비교
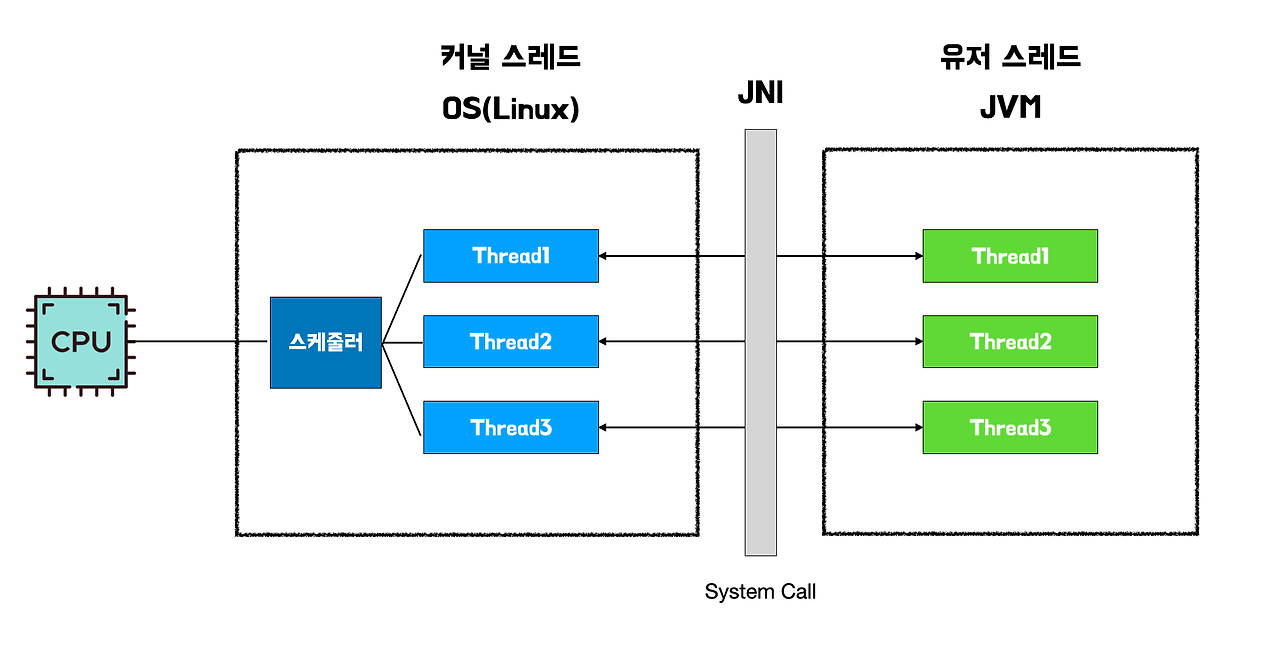
정통 스레드 모델에서는 JVM의 각 스레드가 OS 스레드와 1:1로 직접 매핑됩니다. Java 애플리케이션의 각 스레드가 OS 레벨 스레드를 그대로 쓴다는 뜻입니다. 이 구조에서는 동시 요청이 늘면 OS 스레드 수도 비례해 늘어나고, OS 스레드 수의 제한이 곧 확장성의 천장이 됩니다.
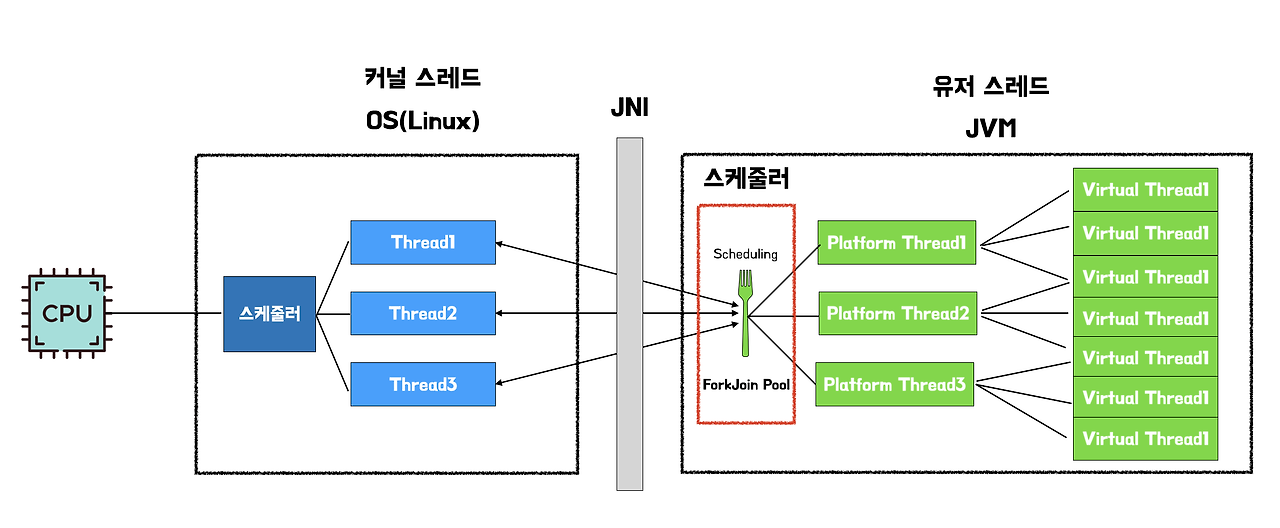
반면 가상 스레드 모델은 많은 가상 스레드가 적은 수의 OS 스레드(Platform Thread)를 공유하는 M:N 매핑 구조입니다. JVM 내부에 ForkJoin Pool 기반 스케줄링 메커니즘이 더해져 가상 스레드를 효율적으로 관리합니다. 이 구조에서 가상 스레드는 필요할 때만 OS 스레드를 잡고, 블로킹 작업이 생기면 OS 스레드를 놓아 다른 가상 스레드가 쓸 수 있게 합니다.
이런 구조 차이 덕에 가상 스레드 모델은 정통 스레드 모델보다 훨씬 더 많은 동시 작업을 효율적으로 처리하고, OS 스레드 자원도 더 알차게 씁니다. 특히 I/O 바운드 작업이 많은 애플리케이션에서 큰 이점을 주며, 시스템 전반의 확장성과 성능을 끌어올립니다.
OS가 큰 가상 주소 공간을 제한된 물리 RAM에 매핑해 풍부한 메모리의 환상을 주듯, Java 런타임은 많은 가상 스레드를 적은 OS 스레드에 매핑해 풍부한 스레드라는 환상을 만들어 냅니다.
가상 스레드는 Java의 기존 Thread API를 확장해 쓰므로, 개발자가 쉽게 적응하고 기존 코드를 최소한의 변경으로 가상 스레드로 옮길 수 있습니다.
단일 가상 스레드 생성 및 실행
Thread.startVirtualThread(() -> {
System.out.println("Virtual thread is running");
});가상 스레드 ExecutorService 사용
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
// 작업 수행
Thread.sleep(Duration.ofSeconds(1));
return i;
});
});
}가상 스레드를 쓸 때 짚어둘 고려사항이 있습니다.
1. 스레드 로컬 변수 사용 최소화
가상 스레드는 매우 가볍고 수가 많아, 각 가상 스레드에 ThreadLocal 변수를 두면 메모리 사용량이 급격히 늘 수 있습니다. 대안으로 Scoped Value를 고려해 봄직합니다.
2. 핀닝(Pinning) 현상
가상 스레드를 쓸 때 꼭 짚어야 할 점이 '핀닝(Pinning)' 현상입니다. 핀닝은 가상 스레드가 특정 OS 스레드에 묶여 다른 가상 스레드로 전환되지 못하는 상황을 가리킵니다. 주로 다음 같은 경우에 일어납니다.
synchronized void potentialPinningMethod() {
// 1. 동기화 블록 내 블로킹 작업
networkService.sendRequest();
// 2. 네이티브 메소드 호출
nativeMethod();
// 3. 긴 실행 시간을 가진 동기화된 코드
for (int i = 0; i < 1000000; i++) {
// 복잡한 연산
}
}가상 스레드는 다룰 내용이 워낙 방대하고 아직 충분히 학습하지 못한 부분도 많아, 다음 포스팅에서 더 자세히 풀어 보겠습니다.
마무리
Java 21의 출시는 Java 언어와 플랫폼이 꾸준히 혁신하며 현대화되고 있다는 점을 잘 보여줍니다. 레코드 패턴과 패턴 매칭은 데이터 중심 프로그래밍을 한층 간결하고 표현력 있게 만들어 주고, 순차 컬렉션은 컬렉션 프레임워크의 일관성과 사용 편의성을 크게 끌어올렸습니다.
특히 가상 스레드의 도입은 동시성 프로그래밍의 패러다임을 바꿔 놓을 만한 변화로 보입니다. 이런 흐름을 보면 Java가 개발자 생산성, 성능 최적화, 현대적 프로그래밍 패러다임 수용 등 여러 방향으로 발전하고 있음이 또렷합니다.